: 深入解析TokenIM训练方法:提升模型性能的最佳2025-10-24 13:19:22
---
### 1. TokenIM训练方法概述
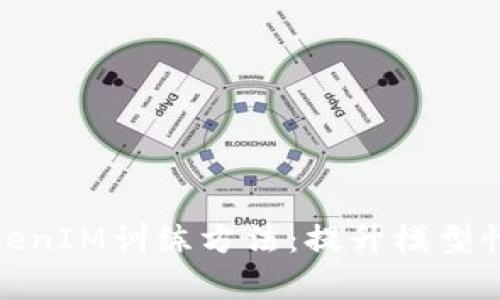
在现代机器学习和深度学习领域,自然语言处理(NLP)成为了一个不断发展的前沿领域。TokenIM训练方法是针对NLP任务模型训练效果的一种新方法,其核心理念是通过精确控制训练过程中的词元(token)处理方式,从而提升模型的理解与生成能力。
TokenIM(Token Improvement Methodology)训练方法强调词元的结构、上下文和语义。这种方法不仅仅是简单的将文本数据输入模型,而是通过细致入微的处理,分析每一个词元在不同语境中的表现,进而指导模型改进其内部表示。
在TokenIM方法中,训练步骤通常包括词元的编码、上下文关系的分析、以及通过反馈调整模型参数等环节。这样的训练过程使得模型在面对复杂的语言结构时,能够展现出更为强大的理解能力。
--- ### 2. TokenIM训练方法的实现步骤 #### 2.1 数据准备与预处理TokenIM训练方法的第一步是对数据进行准备与预处理。这一步骤至关重要,因为训练数据的质量直接影响到模型的表现。
首先,收集适用于特定任务的文本数据。这些数据可以来自于开放的语料库,也可以是特定领域内的专业文本。接下来,进行必要的清洗,包括去除无关的符号、标准化文本格式等。
然后,使用分词工具对文本进行分词处理,形成词元。这里需要注意,分词方式的选择可能会对后续训练产生显著影响,因此选择合适的分词策略至关重要。
#### 2.2 词元编码在TokenIM训练过程中,词元编码是一个关键步骤。常见的编码方法包括词嵌入(Word Embedding),如Word2Vec、GloVe等,这些方法能将词元映射到低维向量空间中。
此外,近年来的技术进步使BERT和GPT等模型的引入成为可能。这些预训练模型不仅能够有效捕捉词元的语义信息,还能通过其深层网络结构强化上下文语境的理解。选择合适的编码方法可以为TokenIM方法奠定良好的基础。
#### 2.3 上下文建模在TokenIM中,上下文建模是一项重要的技术。通过构建上下文关系图,可以帮助模型捕捉词元间的相互关系,从而提升对文本整体的理解能力。
实现上下文建模的方法多种多样,可以利用循环神经网络(RNN)、长短期记忆网络(LSTM)等技术,或者使用更为先进的变换器结构(Transformer)。这些模型都有助于在处理复杂文本时获取长距离依赖信息。
#### 2.4 模型训练与在完成数据准备、词元编码及上下文建模后,接下来便是模型的训练与。在这一阶段,借助反向传播算法和器(如Adam、SGD等)对模型进行训练,逐步调整参数以提升预测效果。
训练过程中,应注意调整学习率、批量大小等超参数,以防止过拟合以及确保模型的收敛性。此外,可以采用验证集来实时监测模型的性能,从而进行针对性调整。
--- ### 3. TokenIM方法的优势 #### 3.1 提高模型的准确性TokenIM训练方法的一个显著优势是提高了模型的预测准确性。通过对词元的精细处理和上下文的深度建模,模型能够更好地理解文本的意义,提高文本处理的精准度。
#### 3.2 强化模型的泛化能力TokenIM还能够显著增强模型的泛化能力。在多样化的语料训练下,模型不仅仅学会了处理特定类型的文本,还能适应不同场景下的语言使用,提升在新数据上的预测表现。
--- ### 4. TokenIM训练方法的应用案例 #### 4.1 机器翻译在机器翻译领域中,TokenIM训练方法展现了巨大的潜力。通过对词元处理的细致分析,模型能够更好地理解源语言与目标语言间的语法和语义对称关系。
在实际应用中,通过引入TokenIM方法的模型能够在翻译准确性和流畅性上超越传统的翻译技术,取得更为优异的成绩。
#### 4.2 情感分析情感分析是NLP中的常见任务,TokenIM训练方法能够帮助模型更准确地识别文本中的情感倾向。通过细致的词元分析,模型能够捕捉到微小的情感差异,更好地解析用户反馈和社交媒体评论。
--- ### 5. 可能相关问题 #### 5.1 TokenIM方法如何与传统方法相比?TokenIM训练方法与传统的NLP训练方法相比,最大的不同是它更加注重词元的处理和上下文的建模。在传统方法中,很多时候仅仅依赖于词频或简易的特征提取,缺少对上下文的深度理解。而TokenIM则通过复杂的模型结构和细致的处理方式,提升了文本处理的准确性。
#### 5.2 如何选择适合的词元编码方法?选择合适的词元编码方式是TokenIM成功的关键之一。常见选择包括传统的Word2Vec和GloVe,以及最近的BERT和GPT等预训练模型。最佳选择往往依赖于具体的任务需求和数据特性,例如,若处理领域特定的文本,BERT模型或许能提供更好的上下文理解能力。
#### 5.3 如何处理TokenIM训练中的过拟合问题?过拟合是机器学习训练中的常见问题,TokenIM训练方法同样需要面对这一挑战。解决过拟合的策略包括使用早停(Early Stopping)、正则化技术(如L2正则化),以及数据增强等方法。通过这些手段,能够有效阻止模型的过拟合现象.
#### 5.4 如何评估TokenIM模型的效果?评估TokenIM模型效果的常用方法包括使用标准的性能指标,比如准确率、召回率和F1值。这些指标能够全面反映模型在特定任务上的表现。此外,还通过可视化工具查看混淆矩阵或ROC曲线来更直观地评估模型质量。
#### 5.5 TokenIM训练方法的未来发展方向?TokenIM训练方法在未来的发展方向上,有望结合更多前沿技术,比如自监督学习(Self-supervised Learning)和多模态学习(Multimodal Learning)。这样的结合将进一步提升模型在复杂任务上的表现,使其能应对更为丰富和多样化的应用场景。
--- 以上部分内容为TokenIM训练方法的概述和详细介绍,并解决了一些相关的常见问题。这一方法的复杂性和多样性,提供了各类研究者和开发者在NLP领域进行探索的良好基础。通过持续的研究和创新,TokenIM有望在未来的自然语言处理任务中扮演更为重要的角色。